This is a paraphrashing of a talk I gave at Agile Singapore 2013 on the subject of DevOps and the Cloud and how they can improve agility in software development.

Lean and Agile are all about shortening feedback loops – get feedback on a product faster, get feedback on your requirements faster, get feedback on your code faster. To do this we need to be able to move quickly.

Over the last decade we’ve got much better at building software. Scrum and XP have helped us get more in tune with the business, build better software and get better results.

But when it comes to actually getting that software out of the door we fall down. There’s two possible scenarios you may have encountered when it comes to releases:

Maybe you’ve had to tackle an Enterprise Ops group. Imagine this - you’ve got the latest release of your whizz bang product ready to go. “Make a release? Sure, we can do that. Just fill in this form in triplicate and we’ll have you up and running in a month.”; “Want to change a system library? Maybe we can do that next quarter if the wind is favourable.”; “Have you had the release form signed off by the senior VPs? If not, it’s back to square one, do not pass go, do not collect $200.”

The other scenario you may have faced is running in cowboy mode. Code gets changed quickly – but that’s because there’s one web server and the files get changed right in production. Deploy the code – but did you actually copy over the right files from your machine? Maybe you missed one? Now it’s not working – but it worked OK on your dev machine. Different library maybe? Time to roll it back – which was the previous version? Was it .old or .old.1 or .old.2? better keep this one around as .doesntwork.bak

In either of these cases you’re not as efficient as you could be. One way to discover this is to do a value stream map. A value stream map is a technique for mapping out a process to discover where you are creating value and where you are creating waste. For each step you measure the elapsed time and the value created. If you were to do a value stream map of your process from having an idea to actually getting it live, where would your waste areas be? I’d take a good bet that a lot of it would be in your release process. So today I’m going to talk through a few ways of improving your release pipeline and how you run your software in production.
Let’s rewind a few years first. Back in the bad old days of software development there was “The business” and “technology”. The two didn’t talk, the two didn’t understand each other, they had opposite views of how to work. Then we adopted Agile and everything became beautiful and now we live in a land of unicorns and rainbows where business folks and tech folks get on, hold hands and build great software. (don’t we?)
However, within technology groups, there’s also traditional divisions. The relationship between developers and operations is very much the same: You’ve got two groups with distinct world views and opposing aims. Developers want to change everything – they want the latest, the greatest, they want to keep pushing out new features. Ops, however, want everything to stay the same. If things stay the same there’s fewer things to break. There’s an immediate point of conflict.
In the last five years or so, a new movements has emerged which aims to fix that.

DevOps is to operations what Agile is to software development. It’s about increasing communication, collaboration and achieving results as a team and not in silos. Like Agile it encourages co-location and cross-functional teams. Beware that it’s also catching on very quickly and, like Agile, it’s attracting people who want to sell you a magic pill or a silver bullet. But DevOps is not a tool, it’s not a methodology, it’s a philosophy. Having a particular tool in your arsenal will not magically solve your problems. It’s very much a cultural change.
Like Agile, there are lots of practices which tend to get bundled together under the “DevOps” umbrella. Typically they are areas where you have some knowledge required of building the software and some knowledge required of running that software. Some of the things that could fall under DevOps and their associated tools are:

Release processes – getting your code out in an automated way
Some examples of tools which can help here include:
- Go – created by Thoughtworks and covers a broad section of the release pipeline including continuous integration (testing) and deployment
- Capistrano – written in ruby and commonly used for deployments to Linux environments for many languages
- Octopus – an example of a tool written for .Net projects on Windows
- Deployinator – by etsy, includes a web front end
- Dreadnot – created by Rackspace, inspired by deployinator and written in node.js

To show you how these tools work, here’s an example of a Capistrano recipe:
set :username, "deploy"
set :host, "myserver01.mydomain"
set :path, "/var/www/html/myapp/"
set :restart, "/etc/init.d/apache2 restart"
set :checkout, "svn export --force"
set :repo, "myrepo.mydomain“
desc "Remote deploy and restart of webserver"
task :deploy, :hosts => "#{username}@#{host}" do
run "#{checkout} #{repo} #{path}; #{restart}"
end
This is a pretty simple example - it inhabits the middle ground between what developers know and what operations know. It includes details such as where to get the application code from and where to deploy it to. To run this you just run “cap deploy”. Once a Capistrano recipe has been created you can deploy it in an automated fashion (e.g. as a post-commit hook or as a scheduled task) or you can use a front-end such as webistrano to allow users to trigger deployments

Monitoring – allowing you to know what your app is doing in production
Some examples include:
- Nagios – the granddaddy of open source monitoring. There are some nice frontends available such as opsview
- NewRelic – SaaS monitoring which does everything from server health to application performance and real user monitoring
- Statsd/ graphite – a newer stack from etsy allowing pluggable metric collection.
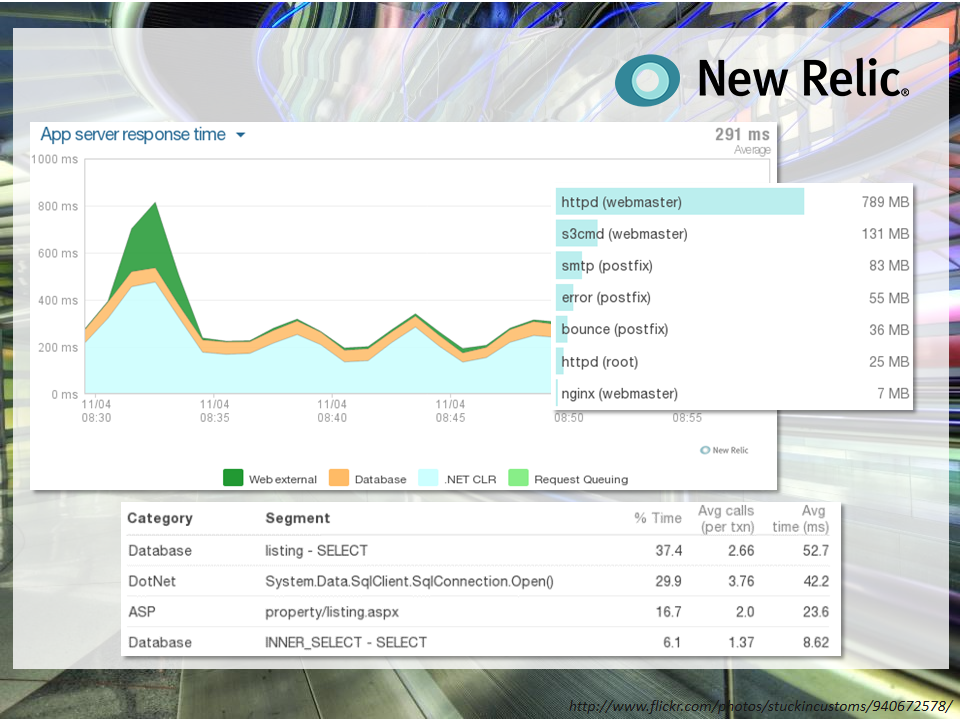
Here’s an example newrelic dashboard. You can see what your users are experiencing using Real User Monitoring. You can see exactly what your app is doing for each request down to the SQL query level. You can monitor servers as well to check on their CPU, memory, I/O, etc.

Configuration management - automating the configuration of your environment to make it consistent and repeatable The two best known tools in this space are:
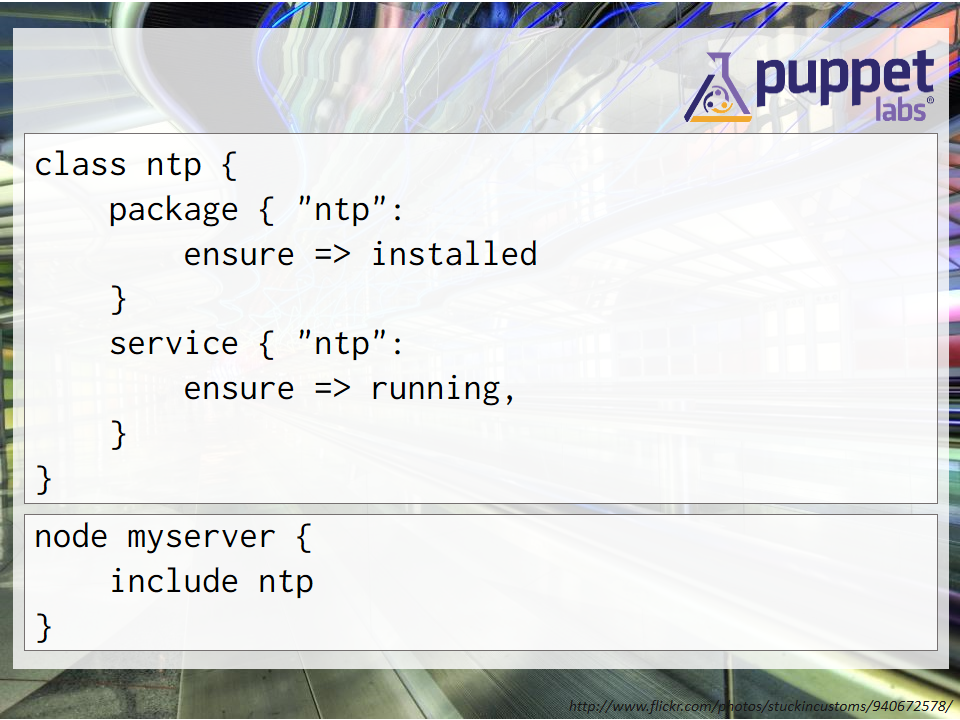
Here’s an example puppet manifest:
class ntp {
package { "ntp":
ensure => installed
}
service { "ntp":
ensure => running,
}
}
node myserver {
include ntp
}
You use familiar programming concepts such as classes and inheritance. You can define services, files and other configuration items and apply them in various combinations to each node (server). Once you’ve written your puppet manifests, the puppetmaster can keep all of the clients in sync so you ensure consistency and repeatability. This is what is known as configuration as code.

Setup dev and test environments - set up development and testing environments easily and repeatably. Some examples of tools in this space:
- Vagrant – making it easy to roll virtual machines in a scriptable way
- Docker – a bundling of linux containers which makes it even faster to run a new environment
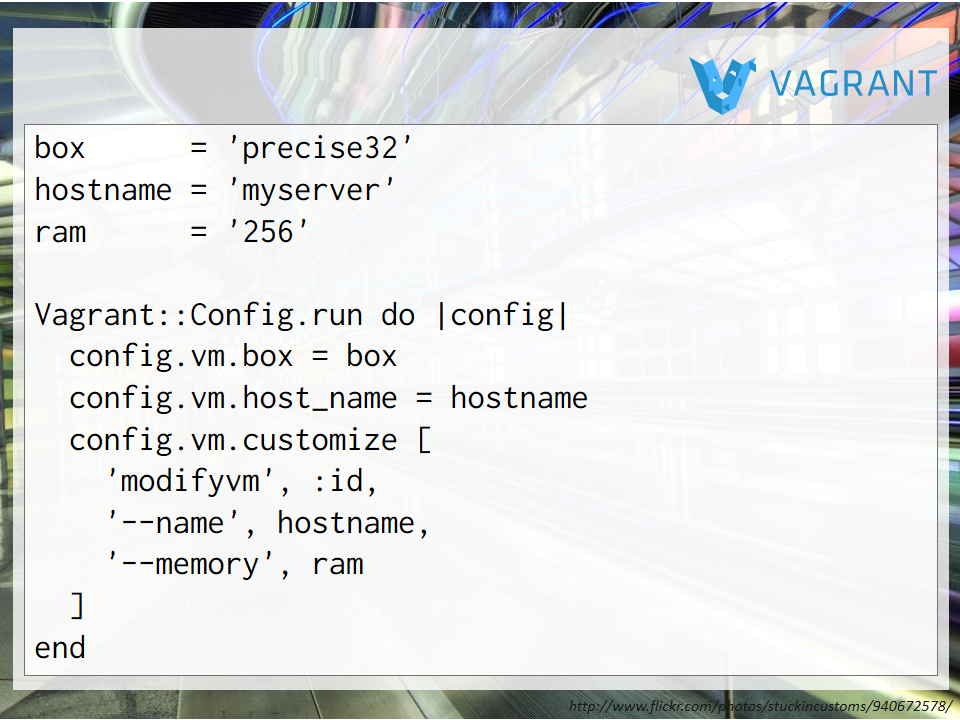
Here’s an example Vagrantfile:
box = 'precise32'
hostname = 'myserver'
ram = '256'
Vagrant::Config.run do |config|
config.vm.box = box
config.vm.host_name = hostname
config.vm.customize [
'modifyvm', :id,
'--name', hostname,
'--memory', ram
]
end
As you can see, we can specify options to configure how our VM will behave. To spin up the VM, we can use pre-made boxes (e.g. Ubuntu distributions) or we can create our own. We can also combine different combinations of boxes and get them all to talk to each other. When combined with puppet we can completely automate building a production-like environment in development or for continuous integration.

Configuration and management of production, development and test environments are even more important when you move to the cloud. Cloud is another term which means many things to many people. In this context I am talking specifically about cloud hosting. Some of the advantages of cloud hosting over traditional infrastructure are:
- Experimentation You can try out new tools or technologies with minimal overhead. And if it’s not working out, just bin it. Want to set up a data processing pipeline? You can do it quickly and cheaply and, if it’s not useful, just throw it away.
- Elasticity You can grow easily as you need to scale. But if you’re automatically scaling, you need to be able to automate the creation of your environments. You can use tools such as Puppet/Chef or your cloud provider may have their own tools.
- Control You can give control to your dev teams to create environments as and when they need them. Importantly you also only pay for the environment while it’s active. Once you’re done, switch if off and you’re not paying any more.
However, when choosing a provider, be wary of cloudwashing - companies who claim to offer a cloud solution but who lack one or more of these attributes. By using these tools and techniques and leveraging cloud hosting, you should be able to build self-sufficiency within your product development teams. Do beware of adding in new layers; one common anti-pattern is to have a separate DevOps team who sit between the development and operations groups. By doing this you end up creating more silos rather than breaking down existing ones. Your aim should be to integrate ops and development so that each team becomes proficient in building AND deploying software.

So how do we get started? As with anything, start small. Some ideas for simple steps to improve your agility:
- Have a kanban wall for ops to improve visibility
- Have ops attend your development standups
- Have developers take turns in on call rotation
- If possible, assign an ops person to each product team
Once you’ve got started, make sure you iterate on your ideas - don’t let the pursuit of perfection distract you from making incremental improvements. You could try doing a value stream map, figure out where your areas of waste are and then start to tackle one area at a time – don’t try and do it all at once.

During this talk I’ve assumed that you’re already doing automated testing and continuous integration. In my mind, it’s a pre-requisite for any steps towards continuous delivery. You need to have confidence in what you’re releasing before you automate any of it. So if you don’t have automated tests, look at that first then look at automating other stages of the pipeline.
I’ve covered a number of third party tools, but remember that it’s not all about acquiring and integrating tools. You also need to look at your own app and how it is architected and how you can make it easier to deploy. Some areas which may help:
- Feature toggles – this is the practice of developing features in your application so that they can be turned on or off by configuration. By doing this you can release code separately from releasing features. Perhaps you want to release a feature out during the working week but only want to launch it at the weekend. Or you might want to test a feature with a subset of users. By architecting features with this in mind you give yourself more flexibility.
- Dark releases – related to feature toggles, this is the practice of releasing a new system to production without actually showing it to your users. This allows you to test your system (for example, to find out if it scales) without impacting your users. One great example of this is the Facebook Chat upgrade; They had the entire infrastructure in place and being sent requests but didn’t show the UI to users so they could iron out all of the problems before a live launch.
- Less interdependence between parts of the systems – the more you can isolate components of your system, the easier it will be to release them separately. By building around APIs and using API versioning, you can make systems less reliant on each other.

Above all though, don’t be afraid to try different approaches – this is still an emerging space and not all of the answers are out there yet. When people first started to do Agile they were clear that good technical practice is a key underpinning of any software development team. All the process in the world won’t make you more efficient if you’re building on a foundation of sand. Along the journey of adopting Agile, we’ve learned that pair programming, test driven development, making technical debt visible have all helped build better software.
Now the focus is on improving our technical practices beyond just the development phase and smoothing the flow from our development machines out to production. DevOps is really no different to Agile – it’s a cultural movement which uses the best human qualities – teamwork, problem solving and communication to deliver better software. I hope I’ve showed you the wealth of tools and techniques which are being developed but remember it’s about you, your team and your organisation - getting those right are key to making this work.

If you’d like to learn more about some of the topics I’ve covered today, I’d encourage you to get hold of Continuous Delivery by Jez Humble and David Farley. I can also recommend Release It! by Michael Nygard. Both will give you plenty of thinking material on how to get into production faster.